SME lending: banks aren’t using enough data
If you are an individual or a small or medium-sized enterprise (SME) aiming to borrow a few thousand to a few hundred thousand dollars, technology has made it possible for lenders to provide an extremely efficient service and for you to get a near-instantaneous credit decision.
This is at the core of alternative lending and peer-to-peer lending companies such as Lending Club, Kabbage, OnDeck, etc.
However, for larger or more complex loans, technology has made fewer inroads into the problem, with lending at the higher end (i.e. loans of $500,000 and above) remaining a fundamentally manual and inefficient process. A bank given the choice of issuing a loan of $100 million with a 1% arrangement fee, delivering a $1 million in fees, or issuing a loan of $10 million with a 1% arrangement fee, delivering $100,000 in fees, will naturally focus on the bigger deal, presenting a barrier to the underwriting of smaller loans, if the process is manual. In the mid-market, where loans are too big for automated decision models but too small for the unit economics of the manual approach to make commercial sense, the market has been characterised by rigid, product-centric lending which does not necessarily meet borrowers’ needs.
While a fully-automated decision process will probably never be appropriate for loans in the millions of dollars, AI and large-scale data analysis can help bridge the gap between fully automated and fully manual credit assessment, allowing an efficient, semi-automated process while still preserving some of the customisation necessary to address the complex needs of SME’s. These platforms will allow banks and lending institutions to significantly improve and accelerate their credit decisions and monitoring capabilities.

Technology has made fewer inroads in complex lending.
Rather than purely relying on backward-looking historical data sourced from the borrower, and scenario analysis based on standard haircuts not necessarily linked to industry drivers (Level one and two analysis banks can pull in a wide range of relevant internal and third-party data sets that enhance credit analysis and create a forward-looking view on the borrower’s business growth through benchmarking) and scenario analysis (Level 3 and 4 analysis).
Sentiment analysis for example can help to summarise qualitative text data into scores which are more readily included in other analysis. Below, we present an example of a restaurant chain, comparing review scores on a popular rating site with the sentiment of text in the reviews. The size of the bubble indicates the number of reviews in the sample. Reviews of restaurants on the diagonal of this plot are normal (a good score corresponds to a positive sentiment and poor scores also correspond with more negative sentiment).
It is more interesting to note the restaurants where the score is positive but the sentiment of text less so or vice versa. Our most anomalous example (labelled “Table one” below) is a restaurant with few reviews, so it may be that the score has been unduly affected by a small number of negative reviews and it will revert to the diagonal as more data points are added. Repeating this analysis for multiple review sites and for a peer set including this chain’s competitors would give a sense for the external perception of the quality of these restaurants and how they compare with peers. This would be important for the understanding of the credit case and allows data-driven validation of the set of comparable businesses used for analysis.
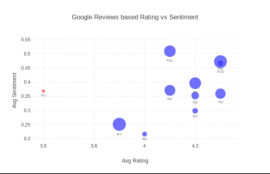
Table one: restaurant data analysis
Clustering is another technique which can be used to create a data-driven segmentation of a given dataset into a set of categories. As such, this allows external validation of assumptions that the analyst might have a priori. The example below is performing an analysis of a spirits manufacturer – when looking at sales data for many brands in the industry, it was difficult for the analyst to discern any particular trends. However, clustering highlighted two brands which were very different. One was seeing a significant sales decline and the other corresponding sales growth. This was related to a demographic change in drinking fashions: young people were changing their habits from one brand to the other. This is in interesting example of AI making data more intuitive and understandable – once the analyst saw the clusters, they were immediately able to explain them.
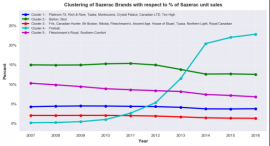
Table two: Clustering can be used to create a data-driven segmentation of any given dataset
There are several benefits to lenders of adopting AI and machine learning when it comes to SME lending. Firstly, because more complex credit situations are now amenable to analysis, they are set free from the shackles of their rigid credit product suite and can offer a wider range of products to meet borrowers’ needs.
They should therefore be able to gain market share by having a differentiated product offering. Secondly, enhanced analysis and better use of external data should lead to better credit outcomes from a more objective, data-driven credit assessment process. Thirdly, they should see greater efficiency from a streamlined, automated process where computers do what they do well (process large amounts of data) and humans do what they do well (provide judgement and expertise). Finally, since they are no longer reacting to the market and fighting to establish a niche in a very competitive space, and can act at speed, they should see margins improve.
By Sean Hunter, CIO of OakNorth



































