Underwriting with alternative and cash flow data
For consumers and small businesses, access to affordable credit plays a crucial role in bridging the gap between short-term cash inflows and outflows as well as in supporting long-term financial health.
Traditionally, access to credit depended on credit reporting and scoring systems that most financial institutions use to assess applications. This leaves out consumers who may have the ability to pay but are scored low, and young consumers who have not had enough time to build credit. Small business credit is often dependent on the credit worthiness of the business owner rather than the potential of the business, potentially limiting their access to credit.
In the data boom of the last decade, financial institutions now have access to a lot more information about their consumers. Use of this non-bureau, “alternative’’ credit data can help better understand the risk of a consumer. Such data can also help reduce operational expenses required to collect and verify consumer documents. For example, having access to a consumers’ bank transactions can help verify the validity of a pay stub when the lender can see bi-weekly income deposits.
Lenders can have access to a variety of different alternative data about their potential consumers. These are roughly divided into two groups – vendor sourced data, and lender generated data. Lenders can generate data about their consumers in several ways. They have visibility on the solicitation source, such as mail offers or direct visits. Cookies can help identify where the consumer comes from, for e.g. a consumer reads a newspaper article about consolidating loans and clicks on an advertisement posted by the lender. Lenders can also use information about how a consumer interacts with the online application and how much time they spend on it.
Vendor based data sources can provide a lot more detailed information about consumers. Information about utility bills and rental payments can be very useful in predicting creditworthiness of a consumer. Educational history can be an indicator of a consumers’ future ability to repay loans. Vendors can also provide access to a consumer’s online activity, which can be an indicator of lifestyle and social choices. Device types and location information using IP addresses can help in tailoring user experiences, but can also be a signal of credit worthiness. And finally, lenders can access the cash flow and bank account information about consumers via vendors. This cash flow data provides signals not present in traditional bureau scores, but – more importantly – it is continuous and real time.
Many fintechs have entered the credit marketplace in the last decade. They almost exclusively operate online, and rely on automated underwriting models and algorithms. Many fintechs originate and hold these loans, while several operate as service providers to traditional banks. Lenders often use services of other technology firms operating in payments, accounting, and data transfer networks. All of this information has to fit into the lender’s automated underwriting algorithms to be able to make an offer to a consumer in real time.
Using alternative data for underwriting
Alternative data can be used to support various aspects of loan underwriting, in calculating intent, pricing elasticity, advanced credit scoring, and detecting fraud. Different sources of data can help with one or more of these tasks.
Competitive loan offers can be made if lenders can generate metrics for consumer “intent”, i.e. the probability that a consumer will accept a given offer. Furthermore, offers can be adjusted if a consumers price “elasticity” is known (price elasticity gives us a percentage change in intent given a unit change in the offer).
Intent can be estimated using several different data sources. In-session signals that track the source of the consumer are very useful. For example, when a consumer arrives after specifically searching for “loan consolidation”, they are more likely to accept an offer. Consumers can arrive from a lender’s blog posts or published content, from their affiliates or after clicking on ads.
Clickstream data can help understand a consumer’s price elasticity. Visiting or applying to a loan from a competitor, not just indicates high intent but also that the consumer is out “shopping” for a deal. A lender can then make a better offer or alternative plans. Other variables that can be used in calculating intent/elasticity include educational history, cash flow, income and other in-session signals generated while the consumer fills out the application.
Lenders can add intent/elasticity modules to their automated underwriting algorithms only if they observe significant improvement potential to their business. Lenders should record all these variables for both originated and rejected loans. Once they have a reasonably large sample, simple statistical testing can show its potential. Intent and elasticity metrics can be generated using logistic regression based models. Other methods or advanced algorithms can also be used depending on the use case.
Cash flow data acquired from a consumers’ bank account transactions can be used for two specific purposes in underwriting. It is often used to verify information provided by the consumer in the loan application, but can also be used to “augment” traditional credit scores. Transaction data allows lenders to take a “second-look” at a loan application when the standard approval process based on traditional bureau based variables would reject the loan. This allows lenders to extend credit to consumers who would otherwise not be served.
Lenders can access this transactional information with the consumer’s approval. Typically, the lender is interested in verifying information the consumer enters in the loan application such as identity, income and employment. The verification task is successful when we observe a series of bi-weekly or monthly payments that add up to the annual income entered by the consumer. The source of these deposits can verify employment information. Incorporating this into an automated underwriting algorithm is quite straightforward and easy.
Cash flow data can also be used to “augment” credit scores. Bureau’s report credit scores, but these are often static in nature and do not account for all financial activity of a consumer. These activities include rental or utility payments (which are not always reported to the consumer reporting agencies), income and expenses. For example, a recent graduate with no significant credit history will be scored low, but can have a steady income, strong evidence of cash-on-hand and a good history of positive balance. Such a consumer is likely to behave like one with a much higher credit score. On the other hand, a consumer with a smaller income-expenses differential may not have the same ability to repay a loan as their credit score would otherwise suggest. Thus, transactional data can be useful to both increase or decrease the assessment of a consumer’s ability to repay a loan.
Calculating these score “differentials”, and incorporating them into an automated underwriting algorithm is not trivial. Risk models will have to be developed and empirically tested to measure their predictiveness. This requires a reasonably sized sample of loan applications associated with their detailed cash flow based data and their loan repayment history. These models can be simple classification models with score bucketing, or more advanced machine learning algorithms when the available data is sufficiently large. Lenders can develop in-house teams to develop these models. Alternatively, they can contract with third-party vendors and use their proprietary algorithms.
Data infrastructure for utilising alternative data
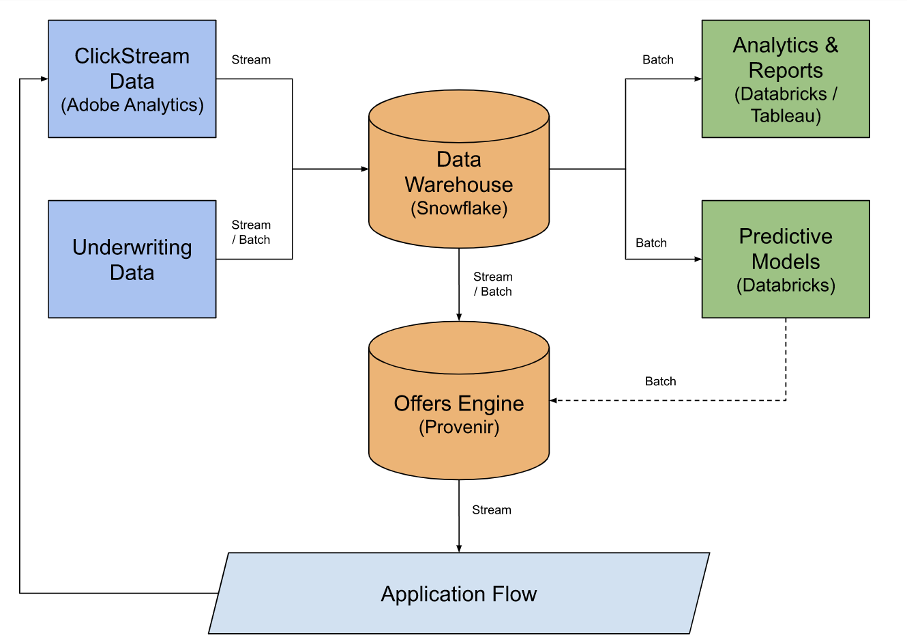
With advances in cloud computing, we can now ingest, process and send triggers back to online applications within seconds. An illustration of the data flow is shown above. The data warehouse serves as the central repository for all current and historical information on the applicant which can then power online and batch systems.
To illustrate the workflow better, we consider the following use case. A customer with an existing banking relationship would like to apply for a personal loan. She has received a pre-approved offer, hence has an invitation code. Her FICO score is on the margin, but she does have a direct deposit with us and has a steady cash flow.
With the power of cloud computing, we can enhance our traditional underwriting models to include other relationships this customer has with us. Furthermore, since she is already a customer, we can initiate an “in-session” chat for any additional information required, so we make a decision while the customer is available. Let’s take a deeper dive into how this will work from a data perspective.
- Customer enters her invitation code in the application start page
- This information is passed to our application service in the middleware layer that returns a customer ID associated with the invitation code.
- We then make a ping to the pHub (Persons Hub) to pre-populate other information associated with the customer
- This gives the customer to authenticate that it is really her and the information supplied is correct
- Once authenticated, we now have the following information on the customer (all linked through the customer ID)
- Risk profile
- Her credit profile using traditional credit data
- Her cash flow using bank information
- Any potential regulatory flags, if applicable
- Offer preferences
- Her primary channel of choice for inbound and outbound communication
- Any friction points she is facing through the application flow, so we can engage her “in-session” or “out-of-session” as applicable
- Risk profile
With the above information, we can now adjust the loan decision real-time with a personalised message, thereby increasing customer engagement.
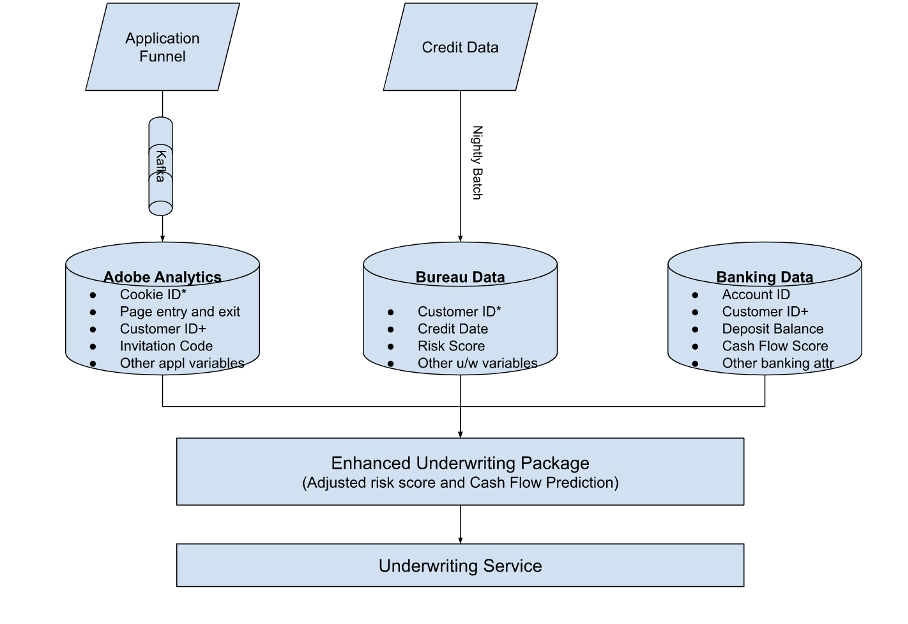
As can be seen from the above flow, the enhanced underwriting package is modular and one can include various other data sources and relationships. This greatly enhances the ability to decide on the margin, and look at data beyond traditional bureau data.




































